
How to use Machine Learning to write engaging titles for Medium articles?
Pre-training DistilBERT transformer on 140,000+ article titles, and serving the resulting model through Huggingface

Pre-training DistilBERT transformer on 140,000+ article titles, and serving the resulting model through Huggingface

Here, I largely follow the approach used in my previous article,
Predicting NASDAQ tweets engagement with BERTweet transformer
Using the BERTweet transformer model to classify highly engaged tweetsmedium.com
using several public datasets of total about 140k+ data science articles published on the Medium website in 2020–2023. Full details of the analysis can be found in this public Kaggle notebook.
Step 1 — data preprocessing
Here, data preprocessing consists of the following steps:
combining datasets from different years;
detecting the title language and selecting articles with titles in English;
selecting the label for binary classification based on whether the recorded number of claps of a given article exceeds 100;
cleaning HTML tags for the title texts with the BeautifulSoup library;
random oversampling of the minority class — articles with positive engagement.
Step 2 — loading and training the model
For training, I use the distilbert-base-cased model that contains about 66 million trainable parameters.
After training the full sample during 5 epochs (the process takes about 1 hour of NVIDIA TESLA P100 GPU available for Kaggle users), the weighted accuracy has increased from 50% (obtained from random oversampling) to about 90%:

Step 3 — check the model performance and save the model to Huggingface
After checking the model performance with a few selected examples:

it becomes clear that rewriting article titles can significantly change the predicted engagement score.
Below is the screenshot of the inference API using the current article title:
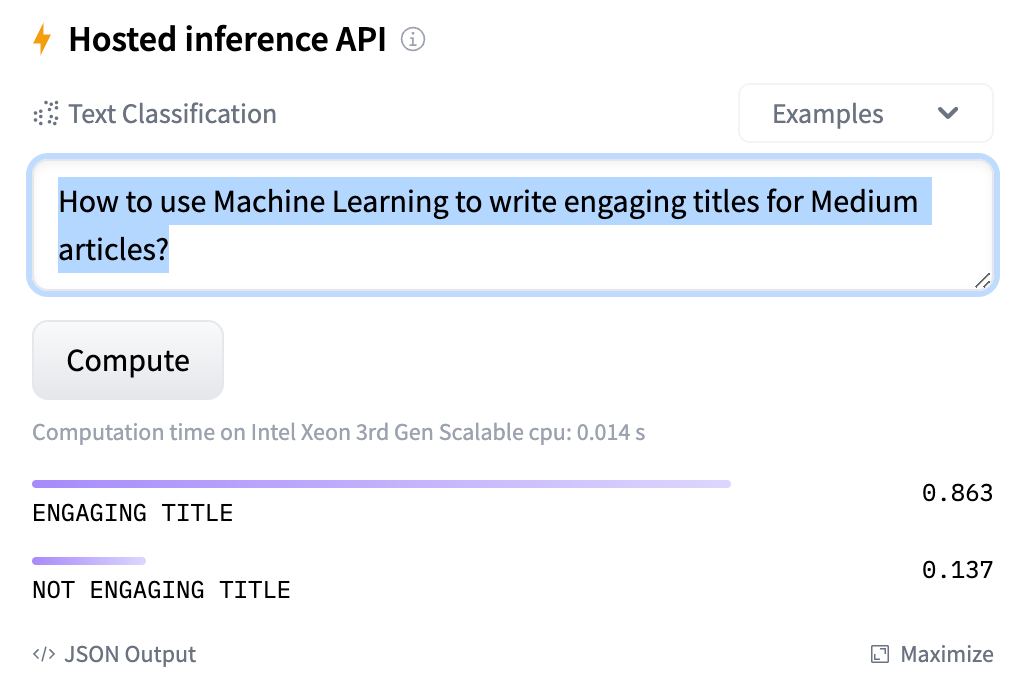
Remarkably, the model predicts that the selected title is engaging with a score of about 86%!
An important caveat while using the model: do not forget that it has been trained on 2020–2023 year articles on the Data Science domain, and thus it cannot reliably track other domains.
I hope these results can be useful for you. In case of questions/comments, do not hesitate to write in the comments below or reach me directly through LinkedIn or Twitter.